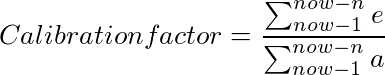
SE-Radio Episode 287: Success Skills for Architects with Neil Ford
WARNING: Unstructured extract from http://www.se-radio.net/2017/04/se-radio-episode-287-success-skills-for-architects-with-neil-ford/
People makes architecture decision even if it not in their title or qualification.
For an architect “soft skills” are essential like presentation skills. Nowadays there are higher standards against architects. Nowadays architect should think of DevOps aspect of the architecture. Architect responsibility is broader than before. Much more thing to consider.
Architects needs to stand meeting. So if you do not be able to stand a meeting then you are fucked up.
There is leadership aspect of software architect.
A really effective one should be good speaker and presenter. Be able to speak not only for technical but to business people.
Most important characteristic of software architect:
- understand technical aspect
- soft skills. Important to find compromised between contradicting parties with different priorities
- express architect vision to business and technical.
- understanding the different nature of knowledge: Depth of knowledge is not as important as the breadth of knowledge. Knowing multiple ways of implementing an architecture/tool is more important than knowing a single tool to implement the architecture. He has to give up certain expertise to in exchange to get more breadth. Broaden your technology knowledge.
- all these “-ilities”: knowing the broader context. Especially broader business aspect: resiliency, scalability, reliability, maintainability, etc. One of these what architects are not emphasizing enough is the feasibility. Should we even try this? Should/could we do that? Timeframe and cost constraints. Understand feasibility.
- understand how a tool might have effect on your architecture.
How to handle not to be as technical as before?:
Keep developing. But not on the critical path. One of the best way to pair with a developer.
- Pair with your team regularly
- see how architecture get to live code.
- guide junior to understand architecture
- see the problem come up in real codebase, etc.
How to transfer essential knowledge to developers
- pair programming is the best for sure.
- a kind of good specification language: certain spec language has the problem of being too tech to a non-tech and not enough tech to a programmer. UML is not a good communication language. Alternative could be C4 model might be suitable because in C4 you have think in different layers and aspect of architecture . (He is giving a summary). It is targeted to different audiences implicitly.
- Lightweight Architecture Decision Records: Text based. Capture essence why we made certain architectural decision. Put into version control. Try to capture the essence why you have made these architecture decision. Do not lose all the analysis work you have made what drive to the conclusion of the usage of current architecture. It could include simple status indication that it is an idea, approved and even that it is implemented and finally removed (as the system is evolved later and it had to change).
Q: Keeping Simple is hard - what do you think?:
Why is it going so complicated over time?
The why things got more complicated because metawork is more interesting then work.
e.g.: Writing a new framework is always more interesting than using an existing one to create something valuable to the company. At the end your job is simply read, put value and write back to database. Metawork is much more brain challenging. (E.g. replacing Angular to React because they “assume” it will be better in the future)
Q: Learn from history. Why is it interesting?:
Learn how to make decision about things (Dreaming in Code book)
Infinite resources (aka no constraint) could still drive to project failure.
Is there any value in the thing we are doing?
“Are we delivering value?”
Q: help young engineer the importance to learn from history:
Not to run into the same problem over and over again.
Component replacement: we think it is like replacing LEGO. But it is more like organ transplantation.
Q: Clever Code:
Useful sometimes but in general it is not good.
Good examples: multi-paradigm languages.
That is the why multi-paradigm languages cause trouble (e.g. Scala). Too many way to do the same things. So it could be difficult to others to understand.
Anytime the tool has SIMPLE in it name that it is probably not simple at all, marketing only (e.g.: sbt, SOAP).
Don’t create too clever stuffs. Developers like creating clever stuffs.
Eliminate complexity!
Be aware of accidental and essential complexity. Example: Routing physical mails. Accidental complexity is when the routing is done by complex character recognition algorithm instead of (e.g.) color code/unit of the paper they use (blue color for unit1, red color for unit2, etc.) what is much simpler.
Bring changes to organization. How?:
“Demonstration defeats discussion”. Stop talking about stuff. Show them how it will be working. Even if a simple version. It will beat complains It helps bypass procrastination. Show them it is useful. Demonstrate and they will see how simple it is. Find a “pain-point”. What is really a problem to them? Solve the problem and demonstrate how it is possible in the “new ecosystem”.
Operations are essential part of software systems. They are part of the feedback loop. (If an operating system upgrade breaks the code it is not the operations who is fixing but developers, so they must cooperate) They must be considered. Even such a things like operating system upgrades. Operation issues are fixed by devs at the end. Move the code to production like system as soon as possible.
Keep the Technical Debt low.
Don’t put road blocks in front of developers. Encourage people to do what they have to do. E.g. We expect to refactor by enforcing to use feature branches. It is punishing when merging. Feature toggle are better from this perspective.
Keep Technical Debt backlog. Be aware of what problems you have in the system. Technical Debt is just the reality. The whole ecosystem is just moving. Thinks was perfect but as the context changed it become a debt/problem/legacy.
Q: How to deal with Code monkeys developing something fast but incorrectly vs other developers who are slow but right and tidying up debt as they go:
Good, solid coder producing good code slowly?
Tracking the wrong thing.
Typing speed is not a productivity indicator. Programming is a creative kind of work.
Pair the slow with fast typers to find balance of quality and speed together.
Most company focus on such a thing like salaries. Like oxygen. Once you have enough it will not be a motivator.
Developers like autonomy on their decision. Giving people more control on their work helps.
Be more like a product base team instead of project based team with good success.
As an architect you have to carefully check metawork (see before) when too much autonomy is given.
High performant team: Nobody knows the secret. Nobody knows how to measure productivity. (OT - actually not true. Team level productivity is clear; individual productivity is the problem - team includes those who are providing requirement :) so all stakeholders :))
Scrum : In fact every project is a marathon not a series of sprint. You could not split a marathon to sprints Sometimes you have to step back and chang and restructure things.
In practice it is very difficult to find what is working and what is not working. Tech Radar helps to discover based on experience. It helps to break from your personal technology bubble. (AKA. learn from others experience)
Every problem is always a people problem. This is a fundamental problem in software.
“Avoid yesterday’s beasts”:
Yesterday’s best practice become today anti-patterns. Most people think anti-pattern is a synonym to “bad”. But instead: it is something initially looked as good idea then turned out to be terribe one, after the fact.
One of the problem is constantly shifting ecosystem we have deal with. Even if you do not change a single bit the entire world is changing around. So even a perfect decision today could be invalidated just because the entire software ecosystem is changing in way we could anticipate. (Subject of evolutionary architecture) (OT- changeability of system is essential goal in the architecture)
“Unknown unknowns” matter the most.
Failure source:
- choosing the wrong architecture what does not support what you want.
- Next shiny thing. Great way to learn new stuff probably not the most effective ways to develop good stuff.
- good architecture start degrading by people because of their own reason.
(OT: For this the architect should be kept in the system the longest, even if he is the most expensive resource, he is the guarantee of the consistency and the responsiveness to the changes)
Microservices are slowly reimplementing everything what we have in CORBA (or SOAP stuff later) because then need to meet the same challenges.
Patterns are repeating themselves.
Pair with existing (good) architect to see whether you like (when you want to be an architect).
Learn architecture pattern books. How to put systems together.
Sep 10, 2017
Musings 14
PatternCraft - Visitor Pattern
Design Patterns explained with StarCraft. Very cool!
How We Release So Frequently
We have a lot of tests
Forward-only Migrations
We don’t roll back database migrations. every database migration we do results in a schema that’s compatible with the new version of our code and the previous one. If we have to roll back a code release (that does happen sometimes) then the previous version is perfectly happy using the new version of the schema.
How we acheive this isn’t with some magical technical solution, but purely by convention. Take dropping a column as an example; how do you release that change? Easy:
Release a version of the code that doesn’t use that column; ensure it is stable / won’t be rolled back.
Do a second release that has a migration to remove the column.
New Code != New Features
Customers should never notice a code release, unless perhaps there’s a dramatic improvement in performance. Every new feature is first released in a hidden state, ready to be turned on with a ‘feature toggle'.
Small Releases
With fast builds, lots of tests, less risky database migrations, and feature changes decoupled from code releases: there’s not much standing in the way of us releasing our code often, but there is a feeback loop here that helps us even further: the more often we release, the smaller the releases can be. Smaller releases carry less risk, letting us release even more often. Frequent releases don’t necessarily imply small releases though - it still requires a bit of convention.
Creating Your Code Review Checklist
If we brainstormed for an hour or two, we could probably flesh this out to be a comprehensive list with maybe 100 items on it. And that’s what a lot of code review checklists look like — large lists of things for reviewers to go through and check.
There are two problems with this.
You can’t keep 100+ items in your head as you look at every method or clause in a code base, so you’re going to have to read the code over and over, looking for different things.
None of the checks I listed above actually require human intervention. They can all be handled via static analysis.
That morale boost is empowering, and it leads to an increased sense of professionalism in the approach to software development. “We trust you to handle your business with code formatting” sends a much better message than, “Let’s see here, did you remember to prepend all of your fields with an underscore?”
there should really be two code review checklists: things the reviewee should do prior to submitting for review and things the reviewer should check.
First, here is an example checklist for a code author
Does my code compile without errors and run without exceptions in happy path conditions?
Have I checked this code to see if it triggers compiler or static analysis warnings?
Have I covered this code with appropriate tests, and are those tests currently green?
Have I run our performance/load/smoke tests to make sure nothing I’ve introduced is a performance killer?
Have I run our suite of security tests/checks to make sure I’m not opening vulnerabilities?
Here is an example checklist for a code reviewer
Does this code read like prose?
Do the methods do what the name of the method claims that they’ll do? Same for classes?
Can I get an understanding of the desired behavior just by doing quick scans through unit and acceptance tests?
Does the understanding of the desired behavior match the requirements/stories for this work?
Is this code introducing any new dependencies between classes/components/modules and, if so, is it necessary to do that?
Is this code idiomatic, taking full advantage of the language, frameworks, and tools that we use?
Is anything here a re-implementation of existing functionality the developer may not be aware of?
It’s also very important that the lists remain relatively brief so that the reviews don’t turn into mind-numbing procedures. You can always modify the checklist and add new things as they come up, but be sure to cull things that are solved problems as your team grows. No matter how hard you try, it’s not going to be perfect. The aim is to catch what mistakes you can and to get better – not to attempt perfection.
18 Lessons From 13 Years of Tricky Bugs
CODING
-
Event order. Can the events arrive in a different order? What if we never receive this event? What if this event happens twice in a row? Even if it would normally never happen, bugs in other parts of the system (or interacting systems) could cause it to happen.
-
Silent failures.
-
If. If-statements with several conditions
-
Else. Several bugs have been caused by not properly considering what should happen if a condition is false.
-
Changing assumptions. Many of the bugs that were the hardest to prevent in the first place were caused by changing assumptions.
-
Logging. Make sure to add enough (but not too much) logging, so you can tell why the program does what it does.
TESTING
-
Zero and null. Make sure to always test with zero and null (when applicable).
-
Add and remove.
-
Error handling. The code that handles errors is often hard to test.
-
Random input. One way of testing that can often reveal bugs is to use random input.
-
Check what shouldn’t happen. to check that an action that shouldn’t happen actually didn’t happen.
-
Own tools. Usually I have created my own small tools to make testing easier.
DEBUGGING
-
Discuss. The debugging technique that has helped me the most in the past is to discuss the problem with a colleague.
-
Pay close attention. Often when debugging a problem took a long time, it was because I made false assumptions.
-
Most recent change. When things that used to work stop working, it is often caused by the last thing that was changed.
-
Believe the user. Sometimes when a user reports a problem, my instinctive reaction is: “That’s impossible. They must have done something wrong.”
-
Test the fix.
"IT is a cost center you say? Ok, let’s shut all the servers down until you figure out what part of revenue we contribute to." - @drunkcod
Your mgrs want data about agile. You try to find some data. But data reinforces your own confirmation bias. @RisingLinda
Aug 29, 2016
Always working estimation techniques: Automatic estimation adjustment
In practice this tool is a re-estimation technique.
-
Estimate using any kind of technique you want
-
During development collect time spent on the task
-
After task completed compute calibration factor
-
apply deviation to remaining task
Characteristic:
-
Adapting to experience change
-
No re-estimation is needed
-
Simple
-
Automatic
-
Surprisingly well working in practice
-
Extra administration to collect actual time spent is a must for this technique
In details:
Given the following tasks:
| Task | Estimate | Actual |
|---|---|---|
t1 |
e1 |
a1 |
t2 |
e2 |
a2 |
t3 |
e3 |
a3 |
t4 |
e5 |
|
t5 |
e6 |
|
t6 |
e7 |
At the moment we are at t3 in development. Use the following formula to calculate calibration factor:
Now we can use this calibration factor to predict how much time we need for future activities. It is normal to see calibration factor of 2 or more in the beginning of the project and then growing and stabilizing at 4 when the project is running at full speed. Keep in mind that it is not a qualification of estimates. Just because your calibration factor is high it do not mean that the team is wrong. All it means that we have more information what is more realistic work effort remaining until delivery.
Note that we should not use these numbers mechanistically. We still have to judge the credibility of what the mathematics tell us and adjust our understanding accordingly.
Variation:
-
adjust by task size categories: intuitively we are expecting different calibration factor based on the size of task. We are expecting smaller factor when the size is small because smaller tasks are more predictable. It make sense to group tasks by size. E.g. Small task (estimation from - 0 to 2), middle and big (more than a week). Then compute and apply calibration factor to each of the category.
-
adjust by developer: same categorization could be done by individual developers or developer groups (expert, beginner, etc).
-
adjust by task type: development tasks could be grouped by dominant activity type: server side development, front-end, database, documentation, etc.
By these adjustment you could fine tune you calibration and you have an always updated and surprisingly effective estimate about the remaining.
Jun 27, 2016
Image merge into single PDF
Recently I run into the problem of merging many images into a single PDF.
I thought that it is a trivial problem so I have had a look at my possibilities on the internet. I have found many possibilities: online pdf generator sites and many-many offline applications doing the same job.
What was really surprising that not everything was completely free and not even open sourced (what is more shareware!!!). I was wondering why? Ok, this is only a theoretical question because I know that not everyone is working in IT. On the other hand accepting the fact what such a simple problems are not trivial to solve is frightening.
Luckily I am a developer (among many other things) so I could write scripts for such a simple problem (actually stackoverflow.com could help a lot to any programmer in this case)
Here it is the script I was using to merge many images in the folder into a single PDF.
import java.io.*;
import org.junit.Test;
import com.google.common.collect.ImmutableList;
import com.google.common.io.Files;
import com.itextpdf.text.*;
import com.itextpdf.text.pdf.PdfWriter;
public class MergePDF {
static ImmutableList<String> img_extensions = ImmutableList.<String> builder().add("jpg").build();
public static void main(String[] args) throws Exception {
Document document = new Document(PageSize.A5);
// Kindle PDF 85x114mm seems to be fine....
PdfWriter.getInstance(document, new FileOutputStream("r:\\result.pdf"));
int indentation = 0;
document.open();
for (File f : Files.fileTreeTraverser().children(new File("r:\\bogyo-es-baboca"))) {
if (!img_extensions.contains(Files.getFileExtension(f.getName())))
continue;
Image image = Image.getInstance(f.getCanonicalPath());
float scaler = ((document.getPageSize().getWidth() - document.leftMargin()
- document.rightMargin() - indentation) / image.getWidth()) * 100;
image.scalePercent(scaler);
document.add(image);
}
document.close();
}
}Some notes about the source:
-
It is used Guava and text as library dependency.
-
Document size should be varied depending on the size of target PDF. The default is A4. For Kindle you should use size of 85x114mm.
-
It doesn’t take the case of rotating images, only for scaling to full page.
Apr 17, 2016
Musings 13
"Simplicity and elegance are unpopular because they require hard work and discipline to achieve and education to be appreciated". Dijkstra
Object-Oriented Programming is Bad
A very good example of improperly introduced concept. Strong opinion and complete ignorance of OO advantages.
And it has some obvious issues:
Around 38:00 he is reasoning that long functions are preferable. I think he is missing the point of splitting a long function into many smaller is also dealing with abstraction level.
Summary: He has problem with encapsulation. So if you are not afraid of encapsulation you could save 45 minutes . :)
On the other hand I already doing mostly procedural/functional programming even in Java. I have data structures and "action" objects without any significant state. If needed I could compose them together into a third object. And it is working quite well.
Feature Toggles
Must have read of feature toggles. It is the new buzzword. Be aware of disadvantages. At the end it is just a few additional IF in you system!
Feature Toggles are one of the worst kinds of Technical Debt
build conditional branches into mainline code in order to make logic available only to some users or to skip or hide logic at run-time, including code that isn’t complete (the case for branching by abstraction).
…
And doing this in mainline code to avoid branching is in many ways a step back to the way that people built software 20+ years ago when we didn’t have reliable and easy to use code management systems.
…
Still, there are advantages to developers working this way, making merge problems go away, and eliminating the costs of maintaining and supporting long-lived branches. And carefully using feature flags can help you to reduce deployment risk through canary releases or other incremental release strategies
…
The plumbing and scaffolding logic to support branching in code becomes a nasty form of technical debt, from the moment each feature switch is introduced. Feature flags make the code more fragile and brittle, harder to test, harder to understand and maintain, harder to support, and less secure.
…
Feature Flags need to be Short Lived
…
it can get harder to support and debug the system, keeping track of which flags are in which state in production and test can make it harder to understand and duplicate problems.
…
And there are dangers in releasing code that is not completely implemented, especially if you are following branching by abstraction and checking in work-in-progress code protected by a feature flag. If the scaffolding code isn’t implemented correctly you could accidentally expose some of this code at run-time with unpredictable results.
…
As more flags get added, testing of the application becomes harder and more expensive, and can lead to an explosion of combinations
…
And other testing needs to be done to make sure that switches can be turned on and off safely at run-time, and that features are completely and safely encapsulated by the flag settings and that behaviour doesn’t leak out by accident (especially if you are branching in code and releasing work-in-progress code). You also need to test to make sure that the structural changes to introduce the feature toggle do not introduce any regressions, all adding to testing costs and risks.
…
More feature flags also make it harder to understand how and where to make fixes or changes, especially when you are dealing with long-lived flags and nested options.
Feature branches and toggles
Not everying is so wrong. Instead of feature toggles you could use proper branching strategies to eliminate feature branch weakness as much as possible.
he argument against feature branches are not just merge problems, but semantic merge problems, such as a method rename. This leads to a fear of refactoring, and
Indeed I see this as the decisive reason why Feature Branching is a bad idea. Once a team is afraid to refactor to keep their code healthy they are on downward spiral with no pretty end.
…
If I’m surprised about refactoring based on a merge, this is a failure in communication from the team.
…
But this assumes a faulty strategy – that large refactorings happen solely in feature branches. But for larger refactorings, these can be thought of features themselves
…
The alternative is a Continuous Integration (across branches)
…
In order to mitigate merge risks, I simply make sure I don’t have long-running branches.
Other readings
Wait, what!? Our microservices have actual human users?
Pragmatic approach of microservices. Build multiple websites which looks like being the same. Even multiple Single page application.
Feb 26, 2016
Groovy pollozó megoldás
Original date: 2013-09-26
Update: 2016-02-23
Azaz, ha jó eszközeid vannak, akkor mindenre van megoldás.
Adott egy speciális probléma. Van egy olyan pici project, ami maven-t használ és egy speciális bytekód utófeldolgozást igényel. Sajnos a maven féle process-classes nem nagyon támogatott az Eclipse pluginomban (feketepont a maven-nek és az Eclipse-nek is).
Ekkor marad parancssor. De ha lúd, akkor legyen kövér: legyen continuous teszting (szerinte ez még a Test First-nél is jobb).
Eddig bemutattam Java-s megoldásokat. Most megmutatom, hogy mennyire egyszerű problémáról van szó, ha megfelelő eszköz van a kezünkben, ez esetben a Groovy
1def job = { 2 String pomPath = /-f <full path to pom>\pom.xml/ 3 String command = /<full path to maven home>\bin\mvn.bat test / 4 String fullCommand = command+pomPath 5 println "Executing "+command 6 def proc = fullCommand.execute() 7 proc.waitForProcessOutput(System.out, System.err) 8} 9 10params = [ 11 closure: job, 12 sleepInterval: 1000, 13 dirPath: /<path to dir to monitor>\src/ 14] 15 16import groovy.transform.Canonical; 17 18@Canonical 19class AutoRunner{ 20 def closure 21 def sleepInterval = 3000 22 // running for 8 hours then stop automatically if checking every 3 seconds 23 def nrOfRepeat = 9600 24 def dirPath = "." 25 long lastModified = 0 26 27 def autorun(){ 28 println "Press CTRL+C to stop..." 29 println this 30 def to_run = { 31 while(nrOfRepeat--){ 32 sleep(sleepInterval) 33 if(anyChange()){ 34 closure() 35 } 36 } 37 } as Runnable 38 Thread runner = new Thread(to_run) 39 runner.start() 40 } 41 42 def boolean anyChange(){ 43 def max = lastModified 44 new File(dirPath).eachFileRecurse { 45 if(it.lastModified() > max){ 46 max = it.lastModified() 47 } 48 } 49 if(max > lastModified){ 50 lastModified = max 51 return true 52 } 53 return false; 54 } 55} 56 57new AutoRunner(params).autorun()
Egyszerűen nagyszerű.
A következő lépés az lehetne, hogy az anyChange() metódus helyett is closure-t használunk.
Ez az implementáció pollozást használ, ami nagyszerű kis projectek esetében, de egy nagyobb könyvtárhierarchiánál, már észrevehetően lelassúl.
Update: Mivel rengeteg helyen használom a mindennapokban kicsit letisztult. Itt egy másik implementáció, ami sokkal esszenciálisabb és persze rövidebb.
1import groovy.io.FileType 2long lastModified = 0 3File dir = new File('./content') 4while (true){ 5 long max = 0; 6 dir.eachFileRecurse (FileType.FILES) { file -> 7 if(max < file.lastModified()) 8 max = file.lastModified() 9 } 10 if(lastModified < max){ 11 recompile() 12 lastModified = max 13 } 14 Thread.sleep(3000) 15} 16 17def recompile(){ 18 println "recompile ${new Date()}" 19 def proc = "c:\\environment\\apps\\ruby-1.9.3\\bin\\nanoc.bat compile".execute() 20 println proc.text 21}
Feb 23, 2016
Always working estimation techniques: 90% confidential interval
By giving an upper and lower bound when estimating something you are explicitly entering into the field of risk management (and in parallel to the field of adult project management).
The technique is very simple: Give two numbers. Give those numbers in which you are 90% confident that the real value (real time spent) will fall into.
Think it through that by having this range you just have much more information then having a single "ideal" number (e.g. ideal men days) or something uncalibrated and incomparable figure (story points). Have a look et the following examples:
-
developing the input form takes 3 story points
-
developing the input form takes 5 ideal days
-
developing the input form take from 4 to 6 days and I am 90 confident in it
-
developing the input form take from 2 to 8 days and I am 90 confident in it
Which one of these 4 examples has more information about the delivery date of that feature? It is obvious and it is using the language of our client (none of the economic schools is teaching about story points but they are teaching statistics very deeply).
Dead simple but not always easy. There are few issues, biases you have to keep in mind and try to avoid to make this technique effective.
Anchoring bias: Once we have a number in our head we tend to gravitate toward it. Even if the anchor number is completely unrelated. A typical example when manager says that he thinks that it will take approximately 2 weeks to complete you will come up something close to it especially when it is not impossible. Without such a "anchor" you might come up with totally different figures…. (most probably more) (Thinking Fast and Slow - Daniel Kahneman)
Some estimators says hat when provide ranges, they think of a single number and then add and subtract an "error" to generate their range. It makes estimation too narrow so overconfident. Looking at each bound alone as a a separate binary question of "Are you sure 95% sure it is over/under this amount?" cures our tendency to anchor.
How to measure anything
— Douglas W. Hubbard
— Douglas W. Hubbard
The solution what is working for me is to reversing the anchoring effect. The technique is very simple. Do not think about the number. Instead of starting with a point estimate and then making it into a range, start with an absurdly wide range and then start eliminating the values you know to be extremely unlikely. It is called "absurdity test"
Example: I want to estimate a simple form with a dozens of input and i want to input validate and store the content. I start with extreme lower bound 10 minutes and extreme upper bound of 1 month. Then I am asking a question to myself: "Am I absolutely (95%) sure that it takes minimum 10 minutes?" Of course the answer is no (just reading the story and test cases takes longer). So I stat calibrating. "What about 1 hours?", "What about 5 hours?". Sooner or later I will reach a figure I am not sure that it is not possible. And the same about the upper bound.
If you want to know more about biases just read Thinking Fast and Slow - Daniel Kahneman or How to measure anything.
Apr 03, 2015
Musings on week 12
The importance of making the test fail
Tests are code. Code is buggy. Ergo… tests will contain bugs. So can we trust our tests? Yes, and especially so if we’re careful. First of all, tests are usually a lot smaller than the code they test (they should be!). Less code means fewer bugs on average. If that doesn’t give you a sense of security, it shouldn’t. The important thing is making sure that it’s very difficult to introduce simultaneous bugs in the test and production code that cancel each other out. Unless the tests are tightly coupled with the production code, that comes essentially for free.
Estimation Games
The apparent inability of I.T. people to accurately estimate the effort, time and cost of I.T. projects has remained an insolvable problem. … poor estimation is one of the major factors in the breakdown of relationships between I.T. people and their clients.
However, in the age of outsourcing and increased competition, the need for I.T. people to more accurately estimate the costs and time-frames for new product delivery has emerged as a critical survival factor for many I.T. groups
Simply, poor estimates lead to a lack of credibility and poor business relationships.
almost all research into improving software estimation miss a vital point: it is people who estimate not machines.
our research has shown that within certain conditions, I.T. people are pretty good at estimating. … t the major precondition for improving estimation accuracy is the existence of an estimation environment free of inter-personal politics and political games.
The good news is that I.T. can estimate better. The bad news is that there are lifetimes of games and refining of games that have to be avoided to do this. .
Doubling and add some
Simply, you figure out [however you can] what you think the task will take and then double it. So a 5 day task is quoted as a 10 day task
Of course, the problem with this game is that everyone knows it why novice players are often caught out by bosses/clients … The other problem is that it never stops. In a version of bluffing as seen in poker, no one knows who has doubled or who have multiplied by eight and so on
Much later, when I was researching material for project management, I found that time and motion studies in the 1950’s had shown that the average lost time [meetings, waiting, talking and so on] in office work was around 50%. So the doubling game was based on some sound research.
Reverse Doubling Option
This is the reverse of the Doubling Game. Simply, the boss or client doubles the estimate that he or she is about to give management or business clients and informs the project manager or programmer analyst that the timeframe is half the timeframe that the boss has told the clients.
The Price is Right/Guess the number I’m thinking of
Boss: "Hi, Mary. How long do you think it will take to add some additional customer enquiry screens to the Aardvark System?"
Here the boss or client is being very nice almost friendly.
Mary: "Gee ….. I guess about 6 weeks or so."
Boss: "WHAAAT!!!! That long!!! You’re joking right?"
…
Mary: "Well, let me think ….. OK, I’ll do it in 3 weeks."
The reality is that the boss has already promised the client XX that the enhancement will be done in 3 weeks but the power of the game is to get the project manager or victim to guess the bosses estimate and then say the estimate [preferably in the presence of witnesses such as other team members]. Notice, it was Mary who said 3 weeks not the boss.
This is a truly excellent game for bosses.
Double Dummy Spit
The X Plus Game
This game is very important in all large organisations and is rooted in the hierarchical power base.
Basically, the person who is either requesting an estimate or informing the team of an estimate/deadline that has been already decided, invokes or blames someone who is "higher up"in the organisation for the fact that the pressure is being put on the team.
Boss: "Look, people, I’m sorry to tell you that you have only 4 weeks to develop the new operating system but, Ms. Bigshot has demanded it by then."
The key to his game is that the Boss is a Level 22 [X] and Ms Bigshot is a Level 32 and is much higher in the organisation [X Plus] than the boss.
Spanish Inquisition
meeting is called to discuss some innocuous topic such as what cookies are to be bought for the coffee breaks. The underlying purpose of the meeting is to get the victim into a room with lots of witnesses to provide the peer-group pressure.
Low Bid/What are they prepared to pay
Suspecting that the $10 million is going to be too much for the business group and wanting to undertake the project because it involves both a high organisation profile and interesting new technology, the project manager deliberately reduces the estimate to some number [say $4 million] that he or she believes the business client will accept.
Gotcha/Playing the Pokies
Extremely advanced estimation game players also learn that the best option when playing the Low Bid/Gotcha game is to delay telling the client that they need to spend additional money until the last moment and to repeat the process many times using smaller increments of $1 million instead of a big $4-6 million hit.
Client: "Hello Project Manager, will my project be delivered next week as promised? After all you have been telling me that things have been going well for the past year and the $4 million that I gave you has been used up?"
PM: "Well, I have some bad news and some good news."
Client: "Uh huh. Give me the bad news."
PM: "The bad news is that the system won’t be ready next week."
Client: "WHAAAT! $$#@@@!!!!!"
PM: "Wait. The good news is that things are going well and if you can find another $1 million we will deliver in 2 months."
Client: "Well I guess so… I don’t have much choice do I?"
Repeat until $6 million is spent or the project manager and/or the client is fired - any way the client looses.
While many people would think that project managers playing this game get fired a lot, the reality is that many organisations recognise that the loss of a project manager can lead to serious project problems. Given that this game is played by experienced project managers, they are often too clever at political games to be fired.
Smoke & Mirrors/Blinding with science
This advanced game is helped by the development of complex estimation techniques such as Boehm’s COCOMO, Putnam’s SLIM and Function Point techniques.
Client: "How long will the Aardvarker System take?"
PM: "Let me see. You have 22 External Inputs, 4 Logical Internal Files, 5 concatenated Enquiries … hmm.. that’s 8 by 24 plus 12 minus risk adjustment, add the Rayleigh Curve simulation, subtract because of the hole in the Ozone layer …. 50 weeks!"
Client: "Totally awesome!"
False Precision
Client: "How long will the Aardvarker System take?"
PM: "Let me see. You have 22.1 External Inputs, 4.8 Logical Internal Files, 5.001 concatenated Enquiries … hmm.. that’s 8.02 by 24.002 plus 12.4 minus risk adjustment, add the Rayleigh Curve simulation, subtract because of the hole in the Ozone layer …. 49 weeks, 1 day and 3 hours plus or minus 1 hour !"
Client: "Totally awesome!"
Of course, readers will understand that at the time the "scientific" estimate was made not even the client clearly understood their own requirements.
It’s time to stop playing and start estimating
We must all become part of the elimination of these games. They hurt our reputation with our business clients [many of whom have also learnt to play them]. They result in our organisations investing money and time in projects that are not good investments. Most importantly, they screw up our projects and we all have to work hard and reduce quality to justify them.
Even if you can’t stop your managers and clients from playing estimation games you can certainly stop playing them with your colleagues and team members.
Maybe there will be a new generation of project people who are not taught these games. It’s up to you.
Mar 18, 2015
Always working estimation techniques - reference to past data
-
How long does it take to put all the dirty place into dishwasher?
-
How long does it take to do the regular weekend shopping?
-
How long does it take to got to work?
What is common in all of the examples that you could give quite accurate estimate about them. But it was not always true. You were not able to tell how long it takes to get to the school when you have just moved to the new town. You had to go a few times then you have collected enough real life experience to answer the question.
And the same can be applied to software projects.
How long did it take last time:
-
to implement new database query?
-
to create new form with a dozens of fields with input validation?
-
to implement new web controller (independently from technology stack - struts, struts2 or spring mvc)?
-
to set up a new development environment?
-
to set up a new server?
-
to implement customization of the core product to a new client?
For the first time the answer is always: "I do no know." But the second time you already have some reference you could use.
Each time we introduced our product to new client there were a need for certain customization. As development manager I was asked all the time how long it will take to customize the new client version? Most of the time this question is asked before knowing anything specific about their needs. But my estimation was always accurate because we did such a customization many times and I had my records. When I got this question I answered: "as long as it is taken for client X"
Why is it so powerful? When you have at least 5 past data (at task level or User story level it is not even a big number; in larger scale it might be problematic) you can be sure that any future data will fall into the range of min and max of these samples with 90% confidentiality.
Rule of Five
There is a 93.75% chance that the median of a population is between the smallest and largest values in any sample of five from that population.
How to measure anything
— Douglas W. Hubbard
— Douglas W. Hubbard
Why is it not used more often?
-
no records about actual execution time
-
non-experienced developers either in business or technology
-
new technology
-
crappy code make estimates unpredictable
If you do not have historical record about your executions you should start collecting them. Many times you do not really need precise bookkeeping about time spent. I am sure that you are remembering how long certain thinks were taken in the past, at least approximately.
New developer is always an something unpredictable. If developer is beginner you should not count on him until he proved to be able to deliver reliably.
Uncle Bob in one of his interview or Clean Coders video were talking about why there are not so many old and experienced programmers. They are there but every year there are so many new, freshly "graduated" programmer that you could not recognize them. They made a quick estimate what is the approximate proportion of experienced developer available and they found that 80% of developers have less then 5 years of experience, worldwide.
What are you expecting from someone having less 5 years of experience in large scale? After how many years of experience can someone made brain surgery or build a bridge over a river, or just simply construct a family house without supervision? Hiring newbie developers is a risk you have to control. You have to invest into hiring more expensive but experienced developers. And do not forget the 10x effect of individual developers.
The lack of business knowledge can be controlled. It is not possible to have a whole development team without the business experience (of course it can be but in that case it is an extraordinary bad management decision). In this case experienced developer is responsible for estimation. Of course, a business training is always needed too. If none of these solutions are working you must pay a big money to hire developer with the relevant business experience. Then you could return to the first solution.
New technology. Hmmm… Do you really need to introduce new technology? As an example. Nowadays the so called Big Data problems triggering the use of so called NoSQL databases. But as I see most of the business does not have big data problem. Most of the business has simple database and SQL tuning problems.
If you say that new technology is a must then the solution is the same as described in the previous paragraphs: experienced one is responsible for the estimates of the less experienced one; training; hire the master of technology.
Crappy code: Sucker. I do not know how to deal with it effectively. This is not a problem when brand new code is written because it does not exists yet. But when you are altering existing shit around you…. From professional point of view I know how to improve the quality of shitty code but I do not know how to bypass unreliable estimates it is causing.
Mar 13, 2015
Non Fiction 2014
Roy F. Baumeister · John Tierney Willpower

I started to read in english but later I continued in hungarian. See later as Akaraterő.
Clear, easy to read but still sciantific book how willpower is working and how to improve it.
It is a must have book.
It goes hanad by hand with the book "Thinking, fast and slow" by Daniel Kahneman
Combining the best of modern social science with practical wisdom, Baumeister and Tierney here share the definitive compendium of modern lessons in willpower. As our society has moved away from the virtues of thrift and self-denial, it often feels helpless because we face more temptations than ever. But we also have more knowledge and better tools for taking control of our lives. However we define happiness-a close- knit family, a satisfying career, financial security-we won’t reach it without mastering self-control.
Roy F. Baumeister · John Tierney: Akaraterő

Miért nem teljesülnek az újévi fogadalmak? Miért fulladnak rendre kudarcba a fogyókúrák? Miért bizonyulunk gyakran képtelennek arra, hogy azzal foglalkozzunk, amivel szándékunkban áll? Hogyan vált korunk emberének egyik legnagyobb problémájává az önkontroll, illetve annak hiánya? Mi voltaképpen az akaraterő? E kérdések megválaszolására nagyon sok, sokszor meglepő eredményeket hozó tudományos vizsgálatot végeztek az elmúlt évtizedekben. Kiderült például, hogy izmainkhoz hasonlóan az akaraterőnk is kimerül, ha túlerőltetjük, ezért ügyesen be kell osztanunk – viszont fejleszthető is. A „többet ésszel, mint erővel” és a „rend a lelke mindennek” népi bölcsességek szellemében számos tippet kapunk ehhez a könyv lapjain, többek között a határidők betartásával, a tennivalók listájának csökkentésével, a figyelemösszpontosítással és a káros szenvedélyektől való megszabadulással kapcsolatban. A szerzők a legfontosabb kutatások leírása és az eredmények elemzése mellett híres emberek élettörténetéből vett példákkal teszik olvasmányossá és közérthetővé mondanivalójukat.
Ha-Joon Chang: 23 dolog, amit nem mondtak el a kapitalizmusról / 23 Things They Don’t Tell You About Capitalism

Vevy populist and it is just a "review" (it is describing why thinks were happening and the reason why it is wrong after it happened). On the other hand it is highlighting the weakness of capitalism.
Did you know (for example) that all theory of smart guy getting Nobel prize failed after getting the prize? There were so many of us start using their theories and started to control economics that finally it turned out that it is not working and cause disaster. As I have mentioned this is just one single interesting fact as an example.
Kenneth H. Blanchard · William Oncken Jr · Hal Burrows: The One Minute Manager Meets the Monkey

Monkey management.
Exactly the same as described in Vezetői időgazdálkodás. If it would not cost 1 pound I did not buy it.
Tom DeMarco · Timothy Lister: Waltzing With Bears

Risk management is project management for adults.
On the other hand I am not sure that I will use all the technique described here. But it helped me understanding why risk management is extremely important and have an other reason not to like Story Points.
Any software project that’s worth starting will be vulnerable to risk. Since greater risks bring greater rewards, a company that runs away from risk will soon find itself lagging behind its more adventurous competition.
By ignoring the threat of negative outcomes—in the name of positive thinking or a Can-Do attitude—software managers drive their organizations into the ground.
In Waltzing with Bears, Tom DeMarco and Timothy Lister—the best-selling authors of Peopleware—show readers how to identify and embrace worthwhile risks. Developers are then set free to push the limits.
You’ll find that risk management
makes aggressive risk-taking possible
protects management from getting blindsided
provides minimum-cost downside protection
reveals invisible transfers of responsibility
isolates the failure of a subproject.
Readers are taught to identify the most common risks faced by software projects:
schedule flaws
requirements inflation
turnover
specification breakdown
and under-performance.
Packed with provocative insights, real-world examples, and project-saving tips, Waltzing with Bears is your guide to mitigating the risks—before they turn into problems.
Dean Leffingwell: Agile Software Requirements

Objective: Good book about requirement. There not so many really practical hint how to collect and manage.
Subjective: Very little value to me. I had most of the knowledge already from other source and experience.
Gojko Adzic: Impact Mapping

As short as valuable.
Must have for project managers.
Alan Shalloway · James R. Trott: Design Patterns Explained

One of the best book in the subject. Nice and realistic examples are used to describe design patterns and basic software development principles.
And it is not only about design patterns. There many section about object oriented programming and design, best practices, development principles etc.

Csányi Vilmos: A kutyák szőrös gyerekek / "Dogs like hairy kids"

Extended studies over If Dogs Could Talk and funny stories about the intelligent of dogs. I love it.

Robert L. Glass: Facts and Fallacies of Software Engineering

Ambivalent.
The first time I read (few years ago) I found not so valuable. After the second read I have recognized why it is describing the truth. After the third time (nowdays) I could appreciate that all facts and fallacies are supported by facts, studies and statistics.
Must have.
Dan Maharry: TypeScript Revealed

I got familiar with TypeScript.
Edward Crookshanks: Practical Software Development Techniques

For not professional developers only. It is just an introduction into many professional practices.
This book provides an overview of tools and techniques used in enterprise software development, many of which are not taught in academic programs or learned on the job. This is an ideal resource containing lots of practical information and code examples that you need to master as a member of an enterprise development team.
This book aggregates many of these „on the job” tools and techniques into a concise format and presents them as both discussion topics and with code examples. The reader will not only get an overview of these tools and techniques, but also several discussions concerning operational aspects of enterprise software development and how it differs from smaller development efforts.
For example, in the chapter on Design Patterns and Architecture, the author describes the basics of design patterns but only highlights those that are more important in enterprise applications due to separation of duties, enterprise security, etc.
The architecture discussion revolves has a similar emphasis – different teams may manage different aspects of the application’s components with little or no access to the developer.
This aspect of restricted access is also mentioned in the section on logging.
Theory of logging and discussions of what to log are briefly mentioned, the configuration of the logging tools is demonstrated along with a discussion of why it’s very important in an enterprise environment.
What you’ll learn
– Version control in a team environment – Debugging, logging, and refactoring – Unit testing, build tools, continuous integration – An overview of business and functional requirements – Enterprise design patterns and architecture
Who this book is for
Student and software developers who are new to enterprise environments and recent graduates who want to convert their academic experience into real-world skills. It is assumed that the reader is familiar with Java, .NET, C++ or another high-level programming language. The reader should also be familiar with the differences between console applications, GUI applications and service/daemon applications.
Charles Duhigg: A szokás hatalma / Power of Habit

Very populist book.
Each of the section is composed as National Geographic movie. There is some interesting story which is artificially made "shocking" to the reader. Then it describes the "fact" and science behind.
The most valuable part of the book is the last section. The whole book is about describing why habits are ruling our life. The book is describing how they are working and why it is so difficult to change (you could not ignore habit but you could change the action to be taken).
And the very last section is giving some hint how to change habit (I am sure that most of us are buying this book for this section only). The real advice is that you should not change the trigger of the habit. You could change the action taken to something less frustrating. And how? Do some experiment until it is succeeded. So try until you become successful.
I had higher expectations.
Mar 01, 2015